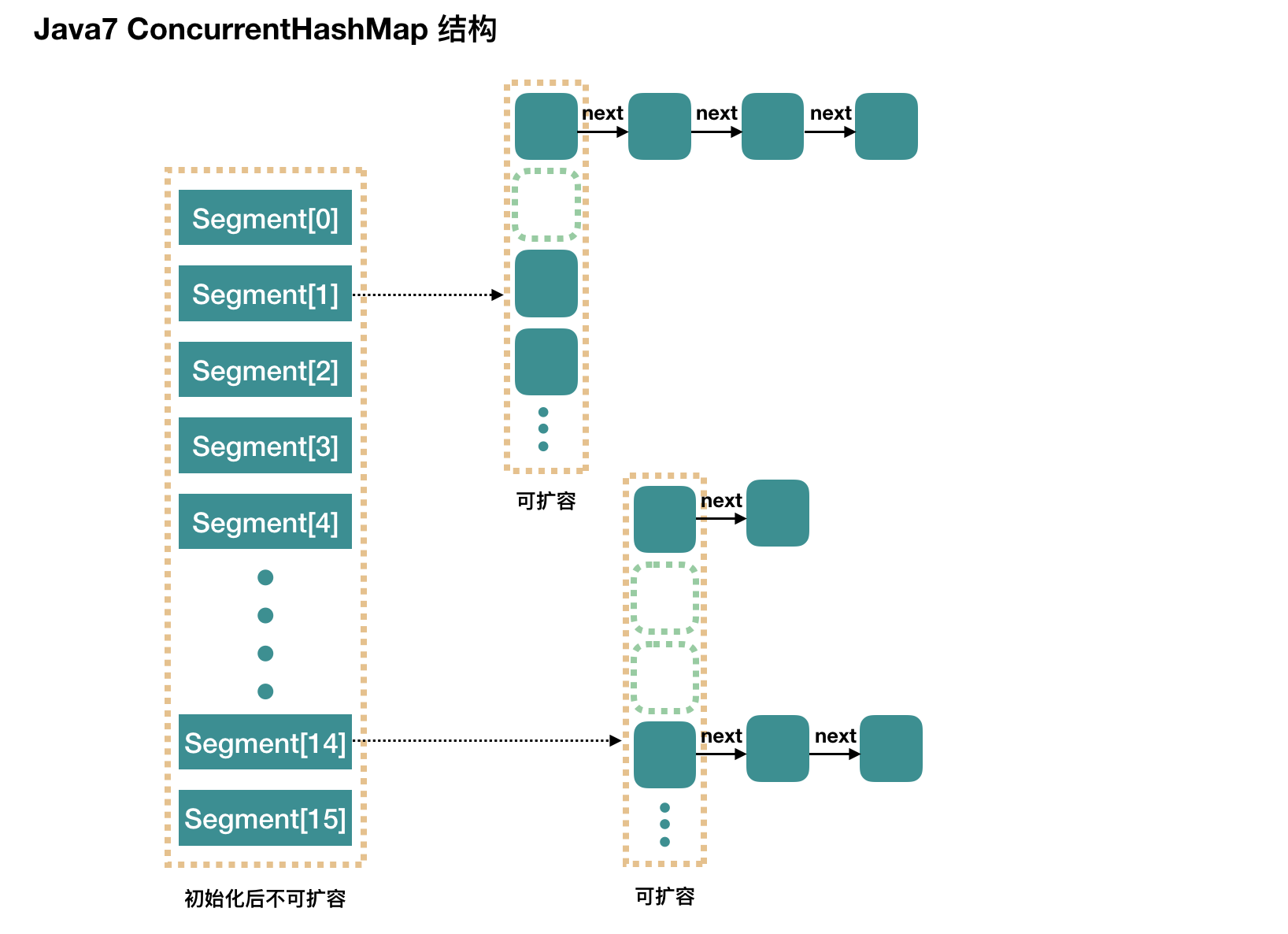
在JDK7中,ConcurrentHashMap是通过分段锁机制来实现的,所谓分段(Segment)是指将一个ConcurrentHashMap拆分成多个Segment,通过保证每个Segment内是线程安全的,从而达到整个ConcurrentHashMap的线程安全。通过将锁的粒度从整个ConcurrentHashMap降为每个Segment以提升并发能力。
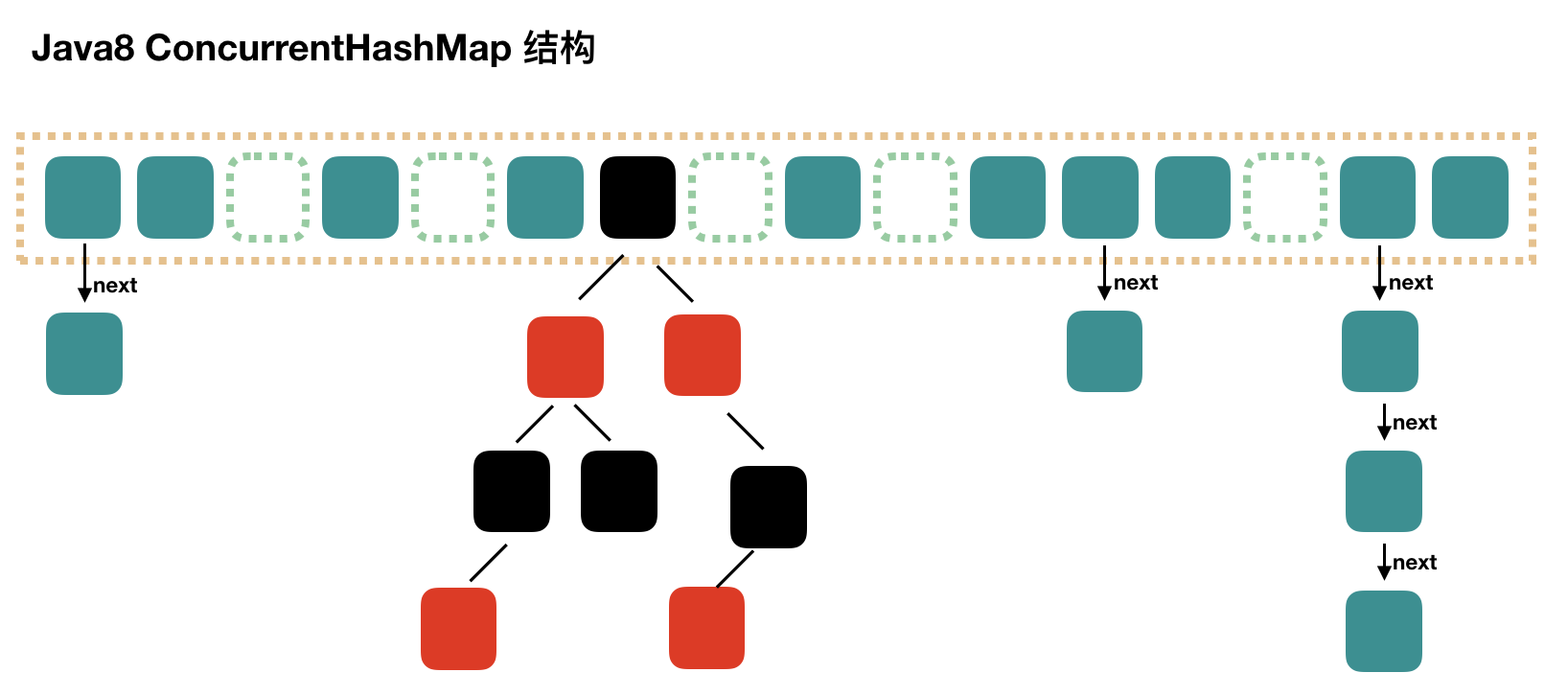
JDK8后,ConcurrentHashMap不再使用Segment这种结构,而是与HashMap一致,但是依旧保留分段锁的思想。原来锁的是每个Segment,现在是锁某个桶,也就是桶的第一个节点。
源码分析
构造方法
1 | // 什么都没做 |
默认的构造方法什么都没有做,各个成员变量都是用默认值。
如果指定了初始容量,通过初始容量,计算了sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】。如 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,得到 sizeCtl 为 32。具体这个sizeCtl是干什么的,由源码可知,它是一个控制标识符,表示哈希表的状态,分负值和非负值两种。
1 | /** |
现在先不管具体的取值,只需要知道,如果调用默认构造方法,sizeCtl是0,如果指定了初始容量,sizeCtl是一个与初始容量有关的2的指数幂。
put方法
由构造方法可以看出,new 完ConcurrentHashMap对象以后,没有进行真正的初始化,真正的初始化逻辑是在put逻辑中。
1 | public V put(K key, V value) { |
先看第七行获取hash值的spread方法,它与HashMap中基本一致,将key的hashcode的高16位和低16位进行异或运算,让低16位融合了hashcode高16位和低16位的特征,不一样的地方是又与HASH_BITS进行了与运算,这一步的作用是将最高位设置为0,也就是说强制这个hash值是正数,至于为什么,下面再说。
1 | static final int spread(int h) { |
initTable方法
真正执行初始化操作的是第13行的initTable()方法。
1 | /** |
根据代码得知,如果当前线程发现sizeCtl小于0,说明有其他线程正在执行初始化或者扩容,那么直接让出时间片,直到tab被初始化完成后返回。如果不小于0,那么通过CAS将sc置为-1,执行初始化操作。sizeCtl为非负数时,分为0和正数的情况,0代表使用的默认构造方法,那么直接使用DEFAULT_CAPACITY作为哈希表的容量,否则使用sc(也就是线程cas成功之前的sizeCtl值)作为哈希表的容量,然后将sizeCtl设置为0.75倍哈希表的容量(sc = n - (n >>> 2))。
由此可以知道,并发场景下,只有1个线程可以成功执行初始化流程,其他线程都会自旋等待直至初始化流程完成。
根据Node类型执行put逻辑
初始化完成后,执行真正的put逻辑,与HashMap一样会根据哈希表索引位置上的Node类型进行不同的put逻辑。不同的时获取Node的方式:f = tabAt(tab, i = (n - 1) & hash)。ConcurrentHashMap没有直接使用tab[i]获取i索引位置上的Node,而是通过tabAt方法,原因在于,哈希表本身(table)标注了volatile关键字保证了可见性和有序性,但是哈希表上的元素并没有,通过tabAt方法可以达到与volatile相似的语义。
Node为null
直接通过cas的方式将元素放置到当前索引位置上。
Node不为null并且hash值为-1
hash值为-1,代表此位置上的Node是ForwardingNode。这里也就说明了前面spread方法为什么要将hash值强制设为正数了,因为负数的hash值是有特殊意义的。
ForwardingNode是一种临时节点,在扩容进行中才会出现,并且它不存储实际的数据。当put方法执行到此时,会调用helpTransfer方法,从名字可以看出来,是帮助扩容的逻辑,具体逻辑等到扩容一起看。
普通put逻辑
如果不是上面两个场景,代码就会执行到前面写了省略号的地方,具体代码如下:
1 | V oldVal = null; |
首先,通过synchronized锁住了哈希表上的这个节点,它可能是一个链表头(next可能为null,也可能不为null)或者是红黑树的根节点。锁住了它,也就相当于锁住了整个桶(bin)。
如果当前哈希表上的Node的hash值是正的,也就是普通Node,那么很简单,待put的元素要么替换要么追加到当前桶的链表上。
如果当前哈希表上的Node是TreeBin也就是当前桶是一个红黑树,执行putTreeVal的逻辑。
addCount方法
put完元素后,还需要做的一步操作是记录当前ConcurrentHashMap有多少个元素。正常思路,我们可以通过cas或者AtomicLong(本质也是cas)保证计数的线程安全,基于cas的操作在高竞争(high contention)的情况下,吞吐量并不好。这里ConcurrentHashMap采用了类似java.util.concurrent.atomic.LongAdder的方法,基于锁分段的思想进行累加的操作。LongAdder可以参看这篇文章。
1 | /** |
简单总结
- 当插入结束的时候,会对 size 进行加一。也会进行是否需要扩容的判断。
- 优先使用计数盒子(如果不是空,说明并发了),如果计数盒子是空,使用 baseCount 变量。对其加 X。
- 如果修改 baseCount 失败,使用计数盒子。如果此次修改失败,在
fullAddCount方法死循环插入。 - 检查是否需要扩容。如果需要走下面的扩容逻辑。
fullAddCount的主要逻辑是:
- 第一次创建时,创建长度为2的CouterCell数组as。获取当前线程的随机数与1做与运算,得到0或者1。将as[0]或者as[1]进行赋值。
- 如果已经存在CouterCell数组as,再判断当前线程与数组长度取余后映射到的as[x]是否为null,如果是null,创建CouterCell对象并赋值;否则cas修改CouterCell对象的value值,如果依然没有成功,则对CouterCell数组进行扩容(长度*2)。重复此步骤直至成功。
- 在对CouterCell数组扩容或者创建CounterCell对象时,都需要抢占cellsBusy作为自旋锁。
扩容
与HashMap不同的是,ConcurrentHashMap的扩容不是通过loadFactor出发的,主要是发生put逻辑的treeifyBin、helpTransfer和addCount这几个方法中。
tryPresize
tryPresize主要是在treeifyBin中调用,当桶中元素个数超过8,但是哈希表长度小于64(也就是16、32)的时候tryPresize会被调用。
1 | // size 传进来的时候是当前哈希表长度的2倍 |
先看49行resizeStamp方法,这是ConcurrentHashMap里一个很重要的方法!
入参代表哈希表的长度,我们假设其是16,numberOfLeadingZeros方法得到的是16的二进制(10000)前面有多少个0,32-5=27。1 << (RESIZE_STAMP_BITS - 1)进行常量替换就是1 << 15,也就是1*215。因此rs = resizeStamp(16)的二进制是0000000000000000 1000000000011011。resizeStamp方法返回了一个只跟当前哈希表长度有关的数(rs),rs的低RESIZE_STAMP_BITS(默认是16,而且好像没有修改的地方)位的最高位一定是以1开头,rs是一个包含了哈希表长度信息的数字,因为哈希表长度一定是2的指数幂,比如16的二进制是10000,32的二进制就是100000,所以numberOfLeadingZeros(n)的结果其实是可以区分不同的哈希表长度的。
紧接着,如果sc>=0,也就是还没有其他线程进行扩容,那么当前线程会进入第42行的分支,将sizeCtl置为(rs << RESIZE_STAMP_SHIFT) + 2,RESIZE_STAMP_SHIFT的值与刚刚计算rs的RESIZE_STAMP_BITS有关:
1 | private static int RESIZE_STAMP_BITS = 16; |
可以认为RESIZE_STAMP_SHIFT的值就是rs高位那些填充的0的个数(上例就是16)。因此rs << RESIZE_STAMP_SHIFT就变成了1000000000011011 0000000000000000,可以看到,最高位是1,代表这是个负数而且很大,sizeCtl为负数并且不等于-1(加不加那个2都不影响它是一个很大很大的负数),代表哈希表正在进行扩容,是不是豁然开朗~
到这里,我们先结合sizeCtl的部分注释,总结下sizeCtl为负数的可能取值及其含义:
When negative, the table is being initialized or resized: -1 for initialization, else -(1 + the number of active resizing threads).
-1代表哈希表正在进行初始化- 非-1的负数,这个地方是网上很多文章写的有问题,而且非常误导的地方,其实也怪这个注解写的有问题。通过刚才的代码我们可以看到,除了-1,
sizeCtl会被cas置为很大很大的负数(rs << RESIZE_STAMP_SHIFT) + 2,不可能是类似-2,-3这类很小的负数,那么-(1 + the number of active resizing threads)代表什么意思呢?其实它是指(rs << RESIZE_STAMP_SHIFT) + 2中后面加的这个2。如果我们把rs << RESIZE_STAMP_SHIFT作为一个基数,这个基数再加上x,x就是(1 + the number of active resizing threads)。那么活跃的扩容线程数(the number of active resizing threads)在这就就是2 - 1 = 1了。如果RESIZE_STAMP_BITS是16的话,那就相当于sizeCtl的高16位代表的是根据当前正在扩容的哈希表扩容前的长度生成的一个stamp,而低16位表示的就是(1 + the number of active resizing threads)。
接着刚才tryPresize方法说,在第42行的else if中,也就是第一个开始扩容的线程将sizeCtlcas置为(rs << RESIZE_STAMP_SHIFT) + 2就相当于表明当前有1个活跃的扩容线程开始进入transfer方法工作啦!
再看回30~40行的分支,也就是:
1 | if (sc < 0) { |
进入此分支,首先需要sizeCtl为负数,代表有其他线程在初始化或扩容。这个分支就会有两个结果:跳出自旋、执行transfer(tab, nt);。这两个if判断会出现在多个地方,除了tryPresize还有addCount和helpTransfer方法中,也就是所有会发生扩容的地方。
先看第二个if判断,它很好理解,就是将参与扩容的活跃线程数+1,然后执行transfer逻辑就行了,与第一个进行本轮扩容的线程的区别在于第二个入参是否为null。
我们主要来看第一个if判断:
(sc >>> RESIZE_STAMP_SHIFT) != rs,结合上面写的就很好理解,就是判断当前线程要参与扩容轮次是不是当前正在进行的一样。因为有可能当前线程在计算完rs后,让出了时间片,那一轮的扩容已经完成了并且已经开始了下一轮,当再获得时间片的时候,当前线程是不应该再继续参与扩容的。sc == rs + 1 || sc == rs + MAX_RESIZERS,之所以把这两个条件放一起,是因为这两个条件应该是存在BUG的,因为sc一定是个负数,而rs一定是一个正数,所以这两个条件不可能成立。正确的写法应该是sc == rs <<< RESIZE_STAMP_SHIFT + 1 || sc == (rs <<< RESIZE_STAMP_SHIFT) + MAX_RESIZERS。那么这两个条件想要表达什么意思呢?sc == rs <<< RESIZE_STAMP_SHIFT + 1表达的是当前活跃的扩容线程数是1 - 1 = 0,没有活跃的扩容线程,没有活跃的扩容线程是指当前扩容操作都已经完成了,之所以sizeCtl还没有被置为正数是因为还有一个参与了扩容操作的线程(不一定真正执行了数据迁移的工作,也许只是调用了transfer但是没有领到任务)正在执行最后的检查操作,具体的看下面的transfer逻辑。sc == (rs <<< RESIZE_STAMP_SHIFT) + MAX_RESIZERS判断的是参与当前这一轮的扩容线程是否已经达到了最大的线程数限制MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1,注意,MAX_RESIZERS最后之所以要减1也是因为1 + the number of active resizing threads。
(nt = nextTable) == null这个判断是获取第一个扩容线程创建好的新哈希表,如果获取不到自然也就终止参与扩容。需要注意的是ConcurrentHashMap源码中大量的使用了这种变量赋值方法,让人头大……transferIndex <= 0如果当前扩容所有的任务都被领完了,当前线程自然也不需要再参与扩容。最后的这两个判断逻辑都会在transfer的逻辑中仔细说。
transfer
transfer方法主要做两个事情:扩大哈希表长度、数据迁移。这个方法会被很多地方调用,比如刚刚的tryPresize、helpTransfer以及addCount。此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。ConcurrentHashMap是支持多个线程并发扩容的,它的思路是这样的,将哈希表分成n段,交给n个线程去并发执行扩容操作。因为扩容后,桶中的元素不是在原索引位置,就是在原索引+原容量的位置上,因此并发扩容不会产生冲突。每段包含几个桶就是步长(stride),同时需要一个全局的指针(transferIndex)来表明哪些桶已经被线程开始处理了。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程。之所以从后往前,是为了防止与迭代发生冲突,迭代操作的下标是从小往大,顺序相反时,二者相遇过后,迭代没处理的都是已经transfer的hash桶,transfer没处理的,都是已经迭代的hash桶,冲突会变少。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
到此为止,就完成了transfer方法的第一个工作:扩大哈希表长度。数据迁移大体的思路是线程通过cas修改transferIndex领取自己的待扩容桶区间也就是一个扩容任务,然后倒序遍历区间内每个桶完成迁移工作。由于逻辑由于分支比较多,就直接看代码的注释吧。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |