并发编程存在的问题
CPU、内存、I/O 设备是计算机体系中重要的组成部分。三者的速度差异非常大,因此为了合理利用CPU,平衡三者的速度差异,在计算机科学的诸多领域都做了努力:
- CPU 增加了缓存,以均衡与内存的速度差异
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用
上述这些举措也是并发编程经常出现问题的源头。
可见性
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。如果是单核CPU,那么多个线程在同一个CPU上执行,一个线程对缓存的写,对另外一个线程来说一定是可见的。如果是多核,每个CPU都有自己的缓存,这时就会造成缓存可见性问题。
原子性
线程是操作系统调度的最小单位,在某个线程的时间片用完后,操作系统会进行线程切换。操作系统做线程切换,可以发生在任何一条CPU指令执行完,但是高级编程语言的一条语句往往对应于多条CPU指令,这就会造我们的一条语句“执行了一半就被切走了”的情况,最终结果与直觉不符。
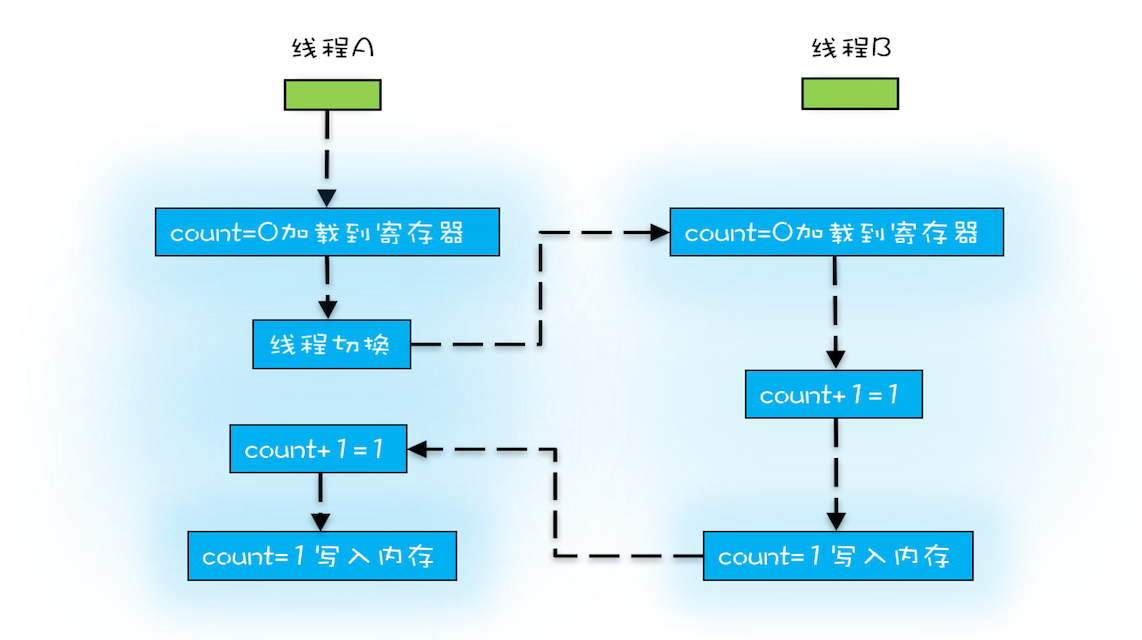
我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。
有序性
有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序。以双重检查创建单例对象为例:
1 | public class Singleton { |
上述代码看似很完美,但是并不能保证线程安全,问题出在new操作上,我们以为的 new 操作应该是:
- 分配一块内存 M
- 在内存 M 上初始化 Singleton 对象
- 然后 M 的地址赋值给 instance 变量
但是优化后可能是:
- 分配一块内存 M
- 将 M 的地址赋值给 instance 变量
- 最后在内存 M 上初始化 Singleton 对象
我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法。那么线程 B 在执行第一个判断时可能会看见线程 A 指令2的操作结果,也就是说instance != null。所以直接返回未经初始化的instance对象。
那么一个可行的解决方案就是将instance变量设置为volatile,禁止指令重排序。这样就能避免线程在未按顺序执行完指令1、2、3之前,获取到instance != null的情况。
Java内存模型解决可见性和有序性
JMM是抽象的协议,屏蔽了各种硬件和操作系统的内存访问差异。它规定了:
所有的变量都存储在主内存中,每个线程还有自己的工作内存,线程的工作内存中保存了该线程使用到的变量(主内存的拷贝),线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成。
但是JMM跟真实硬件内存架构是不同的,线程的工作内存可能包括CPU 寄存器、缓存和主存。
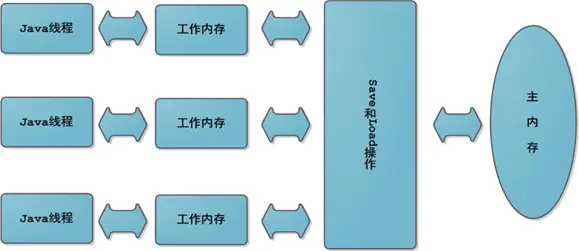
这些概念性的东西,我在第一次看的时候是一脸的懵逼,作为一个程序员,我觉得一点都不接地气。那么先忘掉刚刚看的JMM概念性的东西,换一种角度理解JMM。
我们知道导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决可见性、有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了。合理的方案应该是按需禁用缓存以及编译优化。所以,为了解决可见性和有序性问题,只需要提供给程序员按需禁用缓存和编译优化的方法即可。JMM规范了 JVM 如何提供按需禁用缓存和编译优化的方法。
现在是不是明白一点了呢,也就是说JMM面向的是多种不同的角色。对于使用它的程序员来说,它提供了一套方法保障了可见性和有序性;对于适配底层硬件架构的开发人员来说,它是一套需要实现的规范。很多时候我们看到JMM一脸懵逼的原因,可能是思考的方式不对~
那么JMM为我们程序员提供了哪些工具和方法呢?具体包括:包括 volatile、synchronized 和 final 三个关键字,以及八项Happens-Before规则。
Happens-Before
Happens-Before并不是说前面一个操作发生在后续操作的前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。如果直接看Happens-Before的条款,也是非常晦涩的。先来看一个例子:
1 | class VolatileExample { |
- 程序的顺序性规则
在一个线程中,按照程序顺序,前面的操作Happens-Before于后续的任意操作。这个很好理解,不多说。如果这个都不能保证,单线程也就不线程安全了。 - volatile变量规则
对一个volatile变量的写操作,Happens-Before于后续对这个volatile变量的读操作。保证了单个volatile变量的可见性。 - 传递性
如果AHappens-BeforeB,BHappens-BeforeC,那么AHappens-BeforeC。这条规则可太重要了!以上面的代码为例,假设线程A执行了writer()方法,线程B执行reader()方法,那么执行到第10行时,x会是多少呢?在JDK1.5之前,x可能是42,也可能是0。因为x变量没有标注volatile,无法保证其可见性。但是JDK1.5之后x一定是42,因为JDK1.5增强了volatile语义,也就是增加了上面第二个规则,从而由 aHappens-Beforeb,cHappens-Befored,bHappens-Beforec,推导出aHappens-Befored。 - 管程锁规则
对一个锁的解锁操作 Happens-Before 于后续对这个锁的加锁操作。要彻底理解这个规则需要知道什么是管程,这个之后再讲,现在只需要知道这个规则是针对synchronized关键字,可以理解为,当一个线程离开了synchronized代码块后,另一个线程进入synchronized代码块可以看到之前线程对代码块内变量的修改。 - 线程启动规则
主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。也就是说,如果线程 A 调用线程 B 的 start() 方法(即在线程 A 中启动线程 B),那么该 start() 操作Happens-Before于线程 B 中的任意操作。 - 线程结束规则
线程中任何操作都Happens-Before其他线程检测到该线程已经结束之前。比如如果在线程 A 中,调用线程 B 的 join() 并成功返回或者调用isAlive() 返回false,那么线程 B 中的任意操作Happens-Before于该调用操作的返回。 - 中断规则
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。 - 终结器规则
一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
通过这八项Happens-Before规则,我们就可以保证我们对共享对象的修改能够被其他线程看见啦,一些跟这相关的面试题的答案自然而然就围绕这几项规则了。比如:有一个共享变量 abc,在一个线程里设置了 abc 的值 abc=3,有哪些办法可以让其他线程能够看到abc==3?
我们可以通过在设置了 abc 的值之后再赋值一个volatile变量通过规则2、3“强刷”;或者我们可以直接声明 abc为volatile变量;再或者加synchronized;再或者A线程启动后,使用A.JOIN()方法来完成运行,后续线程再启动之类的运用各种规则都可以实现我们的目的~
volatile
美音读作[ˈvɑːlətl],意思是易变的; 无定性的; 无常性的; 可能急剧波动的。它想表达的是告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。注意这只是它想表达的语义,不是实现原理。
volatile能保证单个变量的可见性,并且通过禁止指令重排序保障有序性,不能保证原子性。volatile具体的实现原理是通过内存屏障,感兴趣的可以看一看这篇文章。
final
volatile表达的是这个变量非常的异变,所以告诉编译器禁用缓存和指令重排序。那如果一个变量生而不变,那么我们可以将它声明为final,这样就相当于告诉编译器,这个变量你可以随便优化~
当然,生而不变的前提是正确的“生”,例如上面双重检查的例子,如果变量在构造函数构造过程中有问题,那也是不行的。但是只要final变量没有在构造函数中“逸出”,那么final就能保证可见性。
synchronized
synchronized关键字由于管程锁规则的原因,能保证可见性和有序性,但是要注意,synchronized作为锁的实现,它要保护的资源是它所锁住的对象,如果要使用一个锁保护多个资源,那么就需要将对多个资源的访问也都上同一个锁,才能保证其可见性和有序性。例如上面双重检查的例子,instance属性的访问并没有被同一个锁所保护,因此synchronized并不能保证instance属性的有序性。
怎样解决原子性问题
上面说了JMM主要解决的是可见性和有序性,那么原子性怎么解决呢?我们知道造成原子性的根源在于线程切换,Java的线程在JDK1.1之后使用的就是Native线程实现了,因此线程切换也就基于CPU中断。显而易见的方案就是禁止CPU中断,禁止CPU中断意味着操作系统不会重新调度线程,获得CPU使用权的线程就可以不间断地执行。这种方案针对只修改一个对象的值是可行的,但是如果应用场景需要一个更大范围的原子性保证,比如对多个属性操作的情况下保证原子性,那需要怎么办呢?
因此,原子性的本质不是多个操作不可分割,不可分割只是外在表现,其本质是多个资源间有一致性的要求,操作的中间状态对外不可见。所以解决原子性问题,是要保证中间状态对外不可见。
所谓中间状态对外不可见是指,如果一个线程正在进行一个原子操作,这个原子操作所涉及的资源在这个原子操作的过程中其他线程是不能访问(包括读取和修改)的。这就需要保证对这些资源的访问,在同一时刻只能有一个线程在进行。这种特性叫做互斥(mutex)。
实现互斥,自然想到的就是锁,我们把一段需要互斥执行的代码称为临界区。线程在进入临界区之前,首先尝试加锁 lock(),如果成功,则进入临界区,此时我们称这个线程持有锁;否则呢就等待,直到持有锁的线程解锁;持有锁的线程执行完临界区的代码后,执行解锁 unlock()。
使用锁进行互斥操作时,始终要在心中明确的一件事就是,锁的是什么,要保护的又是什么!受保护资源和锁之间的关联关系是 N:1 的关系。互斥锁实际上是一把“建议锁”,或者“协同锁”。建议程序中有多线程访问共享资源的时候使用该机制,如果有线程不按规则来访问数据,依然会造成数据混乱。synchronized就是Java中互斥锁的实现,因此synchronized能保证原子性。
至此,synchronized能够保证原子性、可见性、有序性。现在,你可以好好回忆一下synchronized是怎样保证这3个特性的。也可以看看这篇文章。
管程
通过上面的介绍我们知道,我们的程序通过遵守一定的机制,使用synchronized就能解决并发编程中的3种问题,可见性、原子性、有序性。
在刚接触synchronized关键字,第一次看到wait()、notify()、notifyAll()这几个方法时,我是懵的,尤其是碰到比如sleep()和wait()方法的区别这种面试题的时候只能死记硬背。其实这是因为不了解底层的并发编程模型,Java使用管程来解决并发问题,包括对象的重量级锁实现,以及众多JUC包的实现基础,AQS。
如果了解Java对象的内存布局的话,那么一定知道每个对象都有一个与之关联的Monitor对象,这个Monitor对象就代表这个对象的锁。这个Monitor好多文章都翻译为监视器,每次看到我都觉得很别扭,如果学习过操作系统的话,操作系统领域一般都会翻译为管程。我个人觉得还是管程要更好一点。
所谓管程,指的是管理共享变量以及对共享变量的操作过程,让他们支持并发。翻译为Java领域的语言,就是管理类的成员变量和成员方法,让这个类是线程安全的。
在并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。
Java管程的实现参考的是MESA模型。我们先来看看MESA模型是怎样解决互斥的。解决互斥问题的思路很简单,就是将共享变量及其对共享变量的操作统一封装起来。
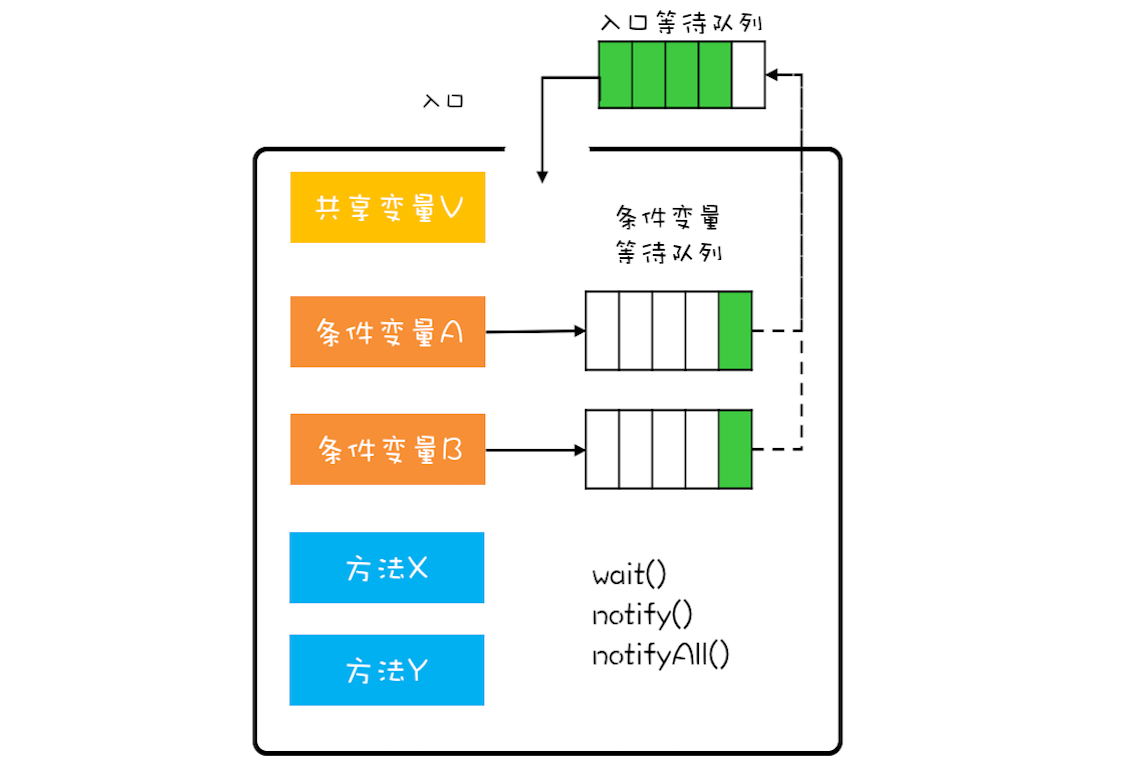
图中最外层的框就代表封装的意思。框的上面只有一个入口,并且在入口旁边还有一个入口等待队列。当多个线程同时试图进入管程内部时,只允许一个线程进入,其他线程则在入口等待队列中等待。管程里还引入了条件变量的概念,而且每个条件变量都对应有一个等待队列,图中条件变量 A 和条件变量 B 分别都有自己的等待队列。
那条件变量和条件变量等待队列的作用是什么呢?其实就是解决线程同步问题。
这里以实现一个线程安全的阻塞队列为例。一个线程安全的阻塞队列要保护的共享变量V就是一个数组,条件A是数组不为空,条件B是数组未满。我们将数组以及对数组元素的增删操作全部封装起来。那么当一个线程A执行出队操作时,首先它需要进入入口,如果入口内已经有其他线程在执行操作,那么当前线程就需要在入口等待队列排队。当线程A进入了入口开始执行出队操作,那么首先需要校验是否满足条件A也就是数组不为空,如果不满足,那么线程A就到条件A的等待队列中等待,此时管程允许其他线程进入。
加入另外一个线程B顺利执行了入队操作,那么线程B需要通知在条件A的等待队列中等待的线程,现在条件A已经满足啦。此时等待的线程A被唤醒后,重新回到入口等待队列,等待进入管程,进而成功执行出队操作。
通过上述流程,管程保证了,同一时刻管程内只有一个线程在执行,同时通过条件变量及对应的等待队列实现了线程间的通信与协作。
synchronized实现原理
Java 参考了 MESA 模型,语言内置的管程(synchronized)对 MESA 模型进行了精简。MESA 模型中,条件变量可以有多个,Java 语言内置的管程里只有一个条件变量。线程进入synchronized代码块,开始执行逻辑,相当于进入管程,管程内的线程通过调用wait()进入唯一的条件变量(锁对象本身)对应的等待队列,管程内的线程通过的调用notify()或者notifyAll()唤醒条件变量等待队列中的线程,重新竞争锁(要不要重新进入入口等待丢列看具体的锁实现)。
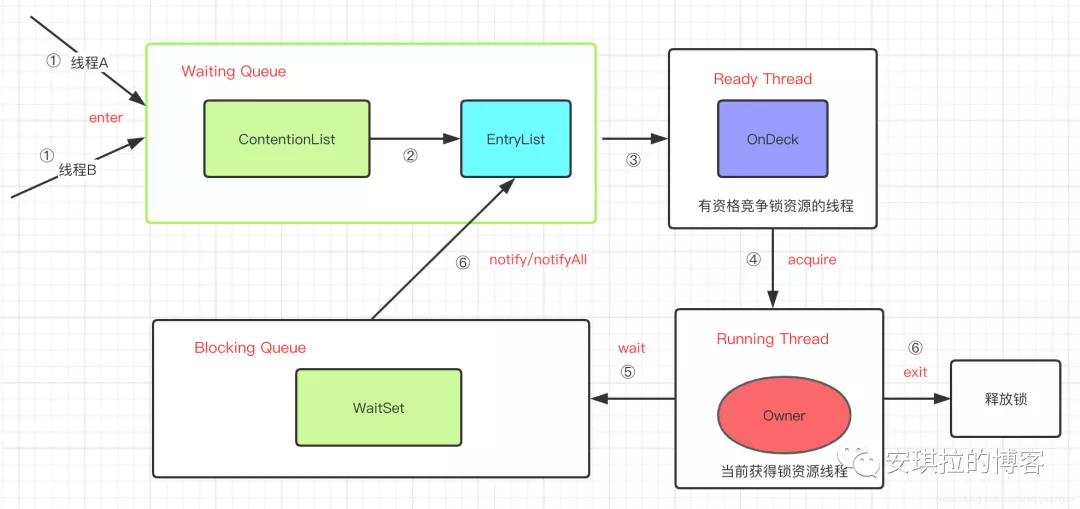
现在再看一些面试题,比如为什么wait()必须在synchronized代码块内执行,或者sleep()和wait()有什么区别的时候知道怎么回答了吧。