线程池大家都听过,属于池化技术的一种,常见的池化技术有数据库连接池、Http连接池等等。之所以会需要池化,一般都是因为“池中”的东西的创建成本比较高,并且可以复用,线程池也不例外。使用方式上,以数据库连接池连接池为例,一般都是从池中获取连接,然后执行操作,最终再将连接归还给连接池。
在Java中,线程池一般是指ThreadPoolExecutor及其变种,它在使用方式上与上面提到的池化技术还是有一些区别的,因为它是Executor框架的实现。

Executor框架
Executor只是一个简单的接口,但它却为灵活而强大的异步任务执行框架提供了基础,该框架能支持多种不同类型的任务执行策略。它提供了一种标准的方法将任务的提交过程与执行过程解耦开来,并用Runnable来表示任务。
1 | public interface Executor { |
Executor基于生产者-消费者模式,提交任务的操作相当于生产者,执行任务的线程则相当于消费者。
线程池
注意,这里所说的线程池是指管理一组同构工作线程的资源池。线程池与工作队列(Work Queue)密切相关,其中在工作队列中保存了所有等待执行的任务。工作者线程(Worker Thread)的任务很简单:从工作队列中获取一个任务,执行任务,然后返回线程池并等待下一个任务。
Executor的生命周期
Executor拓展了ExecutorService接口,添加了一些用于声明周期管理的方法。
1 | public interface ExecutorService extends Executor { |
ExecutorService的生命周期有3种方法:运行、关闭和终止。ExecutorService在初始化创建时处于运行状态。shutdown方法将执行平缓的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完成-包括那些未开始执行的任务。shutdownNow方法将执行粗暴的关闭过程:它将尝试取消所有运行中的任务,并且不再启动队列中尚未开始执行的任务。
在ExecutorService关闭后提交的任务将由Reject Execution Handler来处理。当所有任务都完成后,ExecutorService到达终止状态。
实现原理
看完了上面的这些背景知识,如果我们自己实现一个Executor,思路大概是这样:维护了一个工作队列和一个线程池(工作线程的集合),用户通过调用execute()方法来提交Runnable任务,线程池中的线程阻塞地从工作队列中获取任务,循环往复。ThreadPoolExecutor大致的实现原理与上面类似,只不过在细节上更精巧而已。看下构造方法:
1 | ThreadPoolExecutor(int corePoolSize, |
看下这几个参数的作用:
- corePoolSize:要保留在池中的线程数,即使它们处于空闲状态,除非设置了allowCoreThreadTimeOut
- maximumPoolSize:池中允许的最大线程数
- keepAliveTime & unit:当线程数大于
corePoolSize时,这是多余空闲线程在终止前等待新任务的最长时间。 - workQueue:工作队列,保存的是
Runnable任务 - threadFactory:创建新线程时使用的工厂类,例如可以给线程指定一个有意义的名字。可以不指定这个参数
- handler:如果线程池中所有的线程都在忙碌,并且工作队列也满了,通过这个参数你可以自定义任务的拒绝策略。可以不指定这个参数
可以看到,ThreadPoolExecutor使用BlockingQueue作为工作队列。在向ThreadPoolExecutor提交任务时,ThreadPoolExecutor不是单纯地将任务加到工作队列中,而是配置了corePoolSize和maximumPoolSize两个参数以控制线程池大小。
- 如果运行的线程数少于
corePoolSize,则ThreadPoolExecutor添加新线程而不是排队。 - 如果
corePoolSize或更多线程正在运行,ThreadPoolExecutor将请求排队而不是添加新线程。 - 如果请求无法排队,则会创建一个新线程,除非这会超过
maximumPoolSize,在这种情况下,任务将被拒绝。
简而言之,ThreadPoolExecutor会优先创建corePoolSize个线程并保持住这些线程,之后再提交的新请求如果没有空闲线程,就会排队。如果工作队列是一个有界队列例如ArrayBlockingQueue,那么maximumPoolSize就派上用场了,当队列满了,就会继续创建新的线程,直至达到maximumPoolSize;如果工作队列是一个无界队列,那么maximumPoolSize自然也就没有意义了,线程池的大小永远都小于等于corePoolSize。
runState与workerCount
既然ThreadPoolExecutor使用corePoolSize和maximumPoolSize控制线程池的大小,那么一定需要一个属性记录当前线程池中线程的数量。除此之外,上面有提到ExecutorService有3种生命周期:运行、关闭和终止,ThreadPoolExecutor对其进行了细化。
与其他J.U.C包的一些实现类似,ThreadPoolExecutor通过将Integer类型的32位二进制数进行了拆分,将当前线程数和运行状态封装在了同一个变量ctl中。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
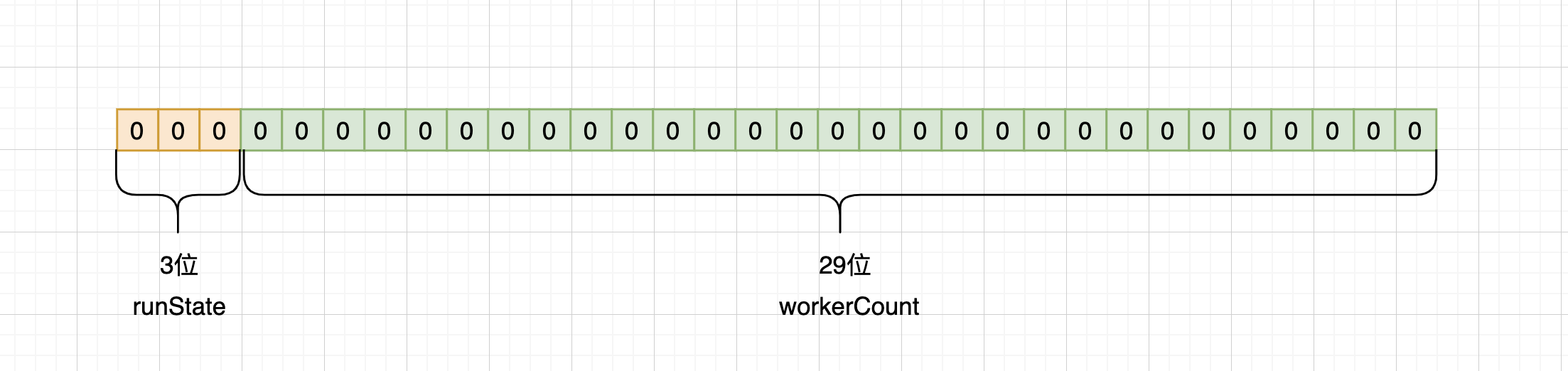
workerCount
The workerCount is the number of workers that have been permitted to start and not permitted to stop.
此值指的是线程池中允许开始运行但没有结束的线程数,也就是有效的线程数,最大值是229-1。
runState
| runState | 描述 |
|---|---|
| RUNNING | 接收新任务,并且也能处理队列中的任务 |
| SHUTDOWN | 不接收新任务,但是却可以继续处理队列中的任务 |
| STOP | 不接收新任务,同时也不处理队列任务,并且中断正在进行的任务 |
| TIDYING | 所有任务都已终止,workercount为0,线程转向 TIDYING 状态将会运行 terminated() 钩子方法 |
| TERMINATED | terminated() 方法调用完成后变成此状态 |
生命周期状态流转:
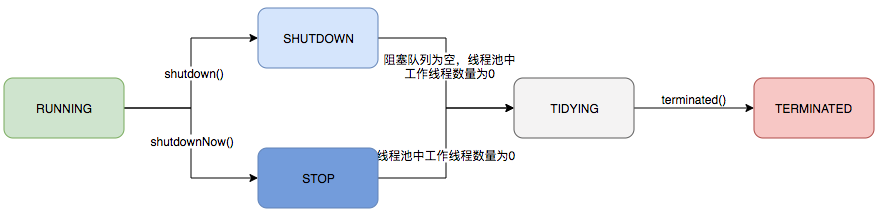
RUNNING是runState的初始状态,为负数,其余状态为单调递增的非负数。
execute
我们通过execute方法向ThreadPoolExecutor提交任务:
1 | public void execute(Runnable command) { |
可以看到execute方法分为3种情况:
workerCount小于corePoolSize,这时新提交的任务直接调用addWorker(command, true)创建一个新的核心工作线程并执行任务就好了。workerCount大于等于corePoolSize,- 通过
offer方法(非阻塞)将任务成功入队。正常来说,入队后等待被工作线程消费就行了。但是有可能此时ThreadPoolExecutor已经不是RUNNING状态了,那么就需要把刚才的入队操作撤销,然后reject。还有一种情况,ThreadPoolExecutor还是RUNNING状态,但是有可能没有有效的线程了(可能所有的线程都凉凉了)。这一步会double-checkrunState的原因在于runState的获取与入队操作不是原子的。 - 入队失败,尝试创建新的非核心工作线程帮助执行新提交的任务,如果失败了,reject。
- 通过
addWorker
这个方法用来创建并启动一个新的工作线程,并且给workerCount+1,都执行成功返回true,其他情况返回false。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
可以看到addWorker方法分为两部分,先通过cas将workerCount+1,然后再创建工作线程并启动。
先看第8到12行
1 | if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) |
想要进入此分支,首先的前提是runState是非RUNNING状态的。在剩余几种状态中,SHUTDOWN是最特殊的,因为处于这种状态时,ThreadPoolExecutor可以继续处理工作队列中的任务。
因此这段代码的含义是:如果runState不是RUNNING状态的话,只有当runState是SHUTDOWN并且firstTask是null而且工作队列不为空才能继续执行addWorker的逻辑。也就是新创建的线程不会直接执行传入的任务,而只可能去帮助消化工作队列中待完成的任务。
第14到25行代码的逻辑就很简单了,通过传入的core变量决定判断workerCount的上界,如果符合要求那么就将workerCount+1。这里需要注意的是,如果core的值传入的是false并且使用addWorker返回值做判断(!addWorker)的情况,都是执行了reject的逻辑。也就是说当workerCount大于等于maximumPoolSize的值时,就会执行决绝策略。
在成功的将workerCount+1之后,需要做的就是创建工作线程并启动它。一直强调工作线程而不是线程的原因在于,ThreadPoolExecutor的线程池中的对象是Worker而不是Thread。
1 | private final HashSet<Worker> workers = new HashSet<Worker>(); |
现在重点关注创建并启动工作线程的逻辑:
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
第11行的锁,锁的是工作线程的set集合workers也就是线程池。如果ThreadPoolExecutor处于RUNNING状态或者处于SHUTDOWN状态,但是先创建的线程需要去帮忙消化工作队列中积压的任务,那么将新建的工作线程加入到workers中。添加成功后,调用第33行的t.start()启动工作线程。到这里向ThreadPoolExecutor提交任务的线程(也就是生产者)就返回了。
runWorker
这个t是在Worker的构造方法中创建的。而默认的DefaultThreadFactory类的newThread方法如下:
1 | public Thread newThread(Runnable r) { |
因为Worker本身也实现了Runnable接口,所以t.start()最终会调用到Worker:::run(),进而执行runWorker方法。
1 | final void runWorker(Worker w) { |
runWorker方法的功能就是执行任务,这个任务要么是传入的firstTask,要么是调用getTask()从工作队列中获取的。当getTask()根据当前的workerCount与corePoolSize的比较关系决定当前获取任务的工作线程是要维持还是退出。如果不需要维持,那么调用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)方法,等待超时返回。如果需要维持,那么调用workQueue.take()一直阻塞。
当getTask()返回null后,由processWorkerExit方法执行工作线程退出逻辑。
注意事项
- 不建议直接使用静态工厂类
Executors创建工厂类,因为其很多方法默认使用的都是无界队列,容易OOM。 - 线程池默认的拒绝策略会 throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制 catch 它,所以开发人员很容易忽略。因此默认拒绝策略要慎重使用。
- 任务在执行的过程中出现运行时异常,会导致执行任务的线程终止。但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。