Change Data Capture 简称CDC,通过记录写入数据库的所有更改,复制到其他系统来保持异构存储系统的数据同步。
数据库的复制日志是数据库写入事件的流,由主节点在处理事务的时候生成。由状态机复制原理可知,每个副本按照相同的顺序处理相同的事件,则所有副本最终都将收敛于相同的最终状态。
CDC的实现
常见的实现方式如下:
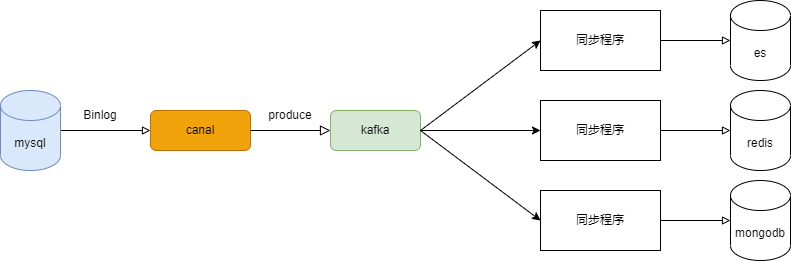
通过如canal等数据库复制日志解析中间件,将复制日志写入基于日志的消息服务中,例如Kafka。在各个异构存储系统前架设各自的同步程序进行数据同步工作。
这里需要关注的几个点:
- 各个业务可以在canal上配置需要监听的表,进而将不同表的复制日志写入到不同的topic中去。
- 消息服务需要保证复制日志的顺序性。
可能存在的问题
实时性
虽然可以将不同业务的复制日志写入到不同的topic。但是对于某一个业务来说,如果发生大数据量、并发高、数据库数据变动频繁时,复制日志的流量会非常巨大。此时同步程序的性能就会成为数据同步实时性的瓶颈,数据就会积压在消息服务中。
我们不能通过多增加一些同步程序的实例数,或者增加线程数来提升处理能力呢?可以,但是需要保证因果一致性。例如,拿订单来说,如果同一个订单的复制日志的顺序是必须严格保证的,但是不同订单之间是无所谓的,所以可以通过按照订单ID将订单数据写入到不同的分区,让同步程序的实例数与分区数相同从而达到提升并发的能力。
数据补偿
同步程序需要考虑数据同步失败的场景。以同步数据到ES为例,如果因为超时等原因,导致写入ES失败,此时需要提交offset完成消费,将失败数据持久化,之后由定时任务去做重试。
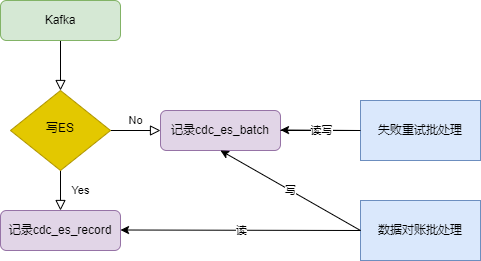
- 失败重试批处理主要负责重试插入失败的记录,并记录重试次数。
- 数据对账批处理会全库检索所有在上次批处理执行完之后有更新的数据,如果record表中不存在或者record表的数据不是最新的,那么插入到batch表中。